Các công cụ Generative AI như Midjourney, Stable Diffusion và DALL-E 2 đã làm say mê chúng ta với khả năng tạo ra những hình ảnh đáng kinh ngạc chỉ trong vài giây.
Tuy nhiên, bất chấp những thành tựu đáng kinh ngạc này, vẫn tồn tại một sự chênh lệch khó hiểu giữa những gì công cụ tạo hình ảnh AI có thể tạo ra và những gì chúng ta có thể làm. Ví dụ, những công cụ này thường không mang lại kết quả đáng mừng cho các nhiệm vụ dường như đơn giản như đếm các đối tượng và tạo văn bản chính xác.
Nếu AI tạo ra sự sáng tạo đến mức chưa từng có, tại sao nó lại gặp khó khăn trong những nhiệm vụ mà cả một học sinh tiểu học cũng có thể hoàn thành?
Khám phá nguyên nhân gốc rễ sẽ giúp ta hiểu rõ hơn về tính toán phức tạp của AI và khả năng tinh tế của nó.
Giới hạn của AI trong việc viết văn bản Con người có thể dễ dàng nhận ra các ký tự văn bản (như chữ cái, số và ký tự) được viết bằng các phông chữ và kiểu viết tay khác nhau. Chúng ta cũng có thể tạo ra văn bản trong nhiều bối cảnh khác nhau và hiểu được cách ngữ cảnh có thể thay đổi ý nghĩa.
Công cụ tạo hình ảnh AI hiện tại thiếu sự hiểu biết bẩm sinh này. Chúng không thực sự hiểu rõ ý nghĩa của các ký tự văn bản. Những công cụ này được xây dựng dựa trên mạng nơ-ron nhân tạo được huấn luyện trên lượng lớn dữ liệu hình ảnh, từ đó chúng "học" được các mối liên kết và thực hiện các dự đoán.
Các kết hợp hình dạng trong các hình ảnh huấn luyện liên kết với các thực thể khác nhau. Ví dụ, hai đường thẳng hướng vào nhau có thể đại diện cho đầu bút chì hoặc mái nhà của một ngôi nhà.
Nhưng khi đến văn bản và số lượng, các mối liên kết này phải rất chính xác, vì ngay cả các sai sót nhỏ cũng dễ dàng nhận thấy. Não bộ của chúng ta có thể bỏ qua những sai lệch nhỏ về đầu bút chì hay mái nhà - nhưng không phải như vậy khi nói đến cách từ được viết, hoặc số lượng ngón tay trên một bàn tay.
Đối với các mô hình từ văn bản thành hình ảnh, các ký tự văn bản chỉ đơn giản là các kết hợp của các đường và hình dạng. Vì văn bản xuất hiện trong nhiều kiểu chữ khác nhau và các chữ cái và số được sử dụng trong sắp xếp không giới hạn, mô hình thường không thể học cách tái tạo văn bản một cách hiệu quả.

AI-GENERATED IMAGE PRODUCED IN RESPONSE TO THE PROMPT ‘KFC LOGO.’
- AI xử lý các chi tiết nhỏ, ví dụ "bàn tay" như thế nào?

Trong các hình ảnh huấn luyện, bàn tay thường nhỏ, cầm đồ vật hoặc bị che khuất một phần bởi các yếu tố khác. Điều này khiến việc liên kết thuật ngữ "bàn tay" với hình ảnh chính xác của bàn tay người với năm ngón tay trở nên khó khăn đối với trí tuệ nhân tạo.
Do đó, bàn tay được tạo ra bởi trí tuệ nhân tạo thường có vẻ dạng không đều, có thêm hoặc thiếu ngón tay, hoặc bàn tay bị che phủ một phần bởi các đồ vật như áo tay hoặc túi xách.
Chúng ta cũng gặp một vấn đề tương tự khi đối diện với các đại lượng. Các mô hình trí tuệ nhân tạo thiếu sự hiểu biết rõ ràng về đại lượng, chẳng hạn như khái niệm trừu tượng "bốn." Do đó, một bộ tạo hình ảnh AI có thể đáp ứng một câu gợi ý về "bốn quả táo" bằng cách dựa vào việc học từ vô số hình ảnh có nhiều lượng quả táo - và trả về một kết quả không chính xác về số lượng.
Nói cách khác, sự đa dạng lớn về các liên kết trong dữ liệu huấn luyện ảnh hưởng đến độ chính xác của các đại lượng trong kết quả.
- Liệu AI có khả năng viết và đếm?
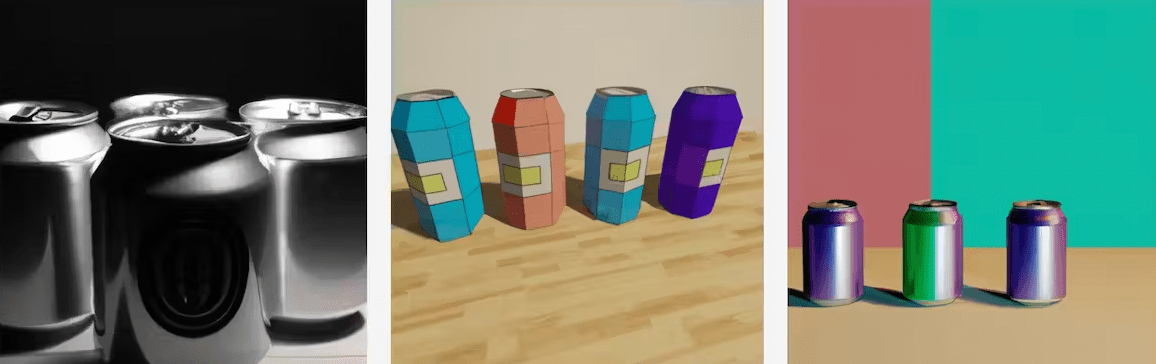 THREE AI-GENERATED IMAGES PRODUCED IN RESPONSE TO THE PROMPT ‘5 SODA CANS ON A TABLE.’
THREE AI-GENERATED IMAGES PRODUCED IN RESPONSE TO THE PROMPT ‘5 SODA CANS ON A TABLE.’
Cần nhớ rằng việc chuyển đổi văn bản thành hình ảnh và video là một khái niệm tương đối mới trong lĩnh vực trí tuệ nhân tạo. Các nền tảng tạo hình ảnh hiện tại chỉ là phiên bản "độ phân giải thấp" của những gì chúng ta có thể kỳ vọng trong tương lai.
Với sự tiến bộ đang được thực hiện trong quá trình huấn luyện và công nghệ trí tuệ nhân tạo, trong tương lai, các trình tạo hình ảnh AI sẽ có khả năng tạo ra các hình ảnh chính xác hơn nhiều.
Đáng chú ý rằng hầu hết các nền tảng AI công cộng hiện tại không cung cấp mức độ năng lực cao nhất. Tạo ra văn bản và số lượng chính xác đòi hỏi mạng lưới được tối ưu hóa và tùy chỉnh một cách tối đa, vì vậy việc đăng ký trả phí cho các nền tảng tiên tiến hơn sẽ có khả năng mang lại kết quả tốt hơn.
Bài viết này được dịch từ The Conversation dưới giấy phép Creative Commons.






")